这是一篇初学Hadoop时应该浏览的博客,受18年实习时的mentor推荐,我读了Understanding Hadoop Clusters and the Network一文,并在这里翻译一遍。
Understanding Hadoop Clusters and the Network
Author: Brad Hedlund
Link: original text
Translator: Yanss
This article is Part 1 in series that will take a closer look at the architecture and methods of a Hadoop cluster, and how it relates to the network and server infrastructure. The content presented here is largely based on academic work and conversations I’ve had with customers running real production clusters. If you run production Hadoop clusters in your data center, I’m hoping you’ll provide your valuable insight in the comments below. Subsequent articles to this will cover the server and network architecture options in closer detail. Before we do that though, lets start by learning some of the basics about how a Hadoop cluster works. OK, let’s get started!
本文是系列的第1部分,将带你详细了解Hadoop集群的架构和方法,以及它如何将网络和服务器基础设施相关联。这里介绍的内容主要是基于学术研究和我与在实际产品中运行集群的客户的交流。如果你在你的数据中心中运行Hadoop集群生产,我期待你在下面的评论中提供有价值的见解。接下来的文章将会包含服务器和网络结构的详细细节。然而在此之前,让我了解一些Hadoop集群工作的基础。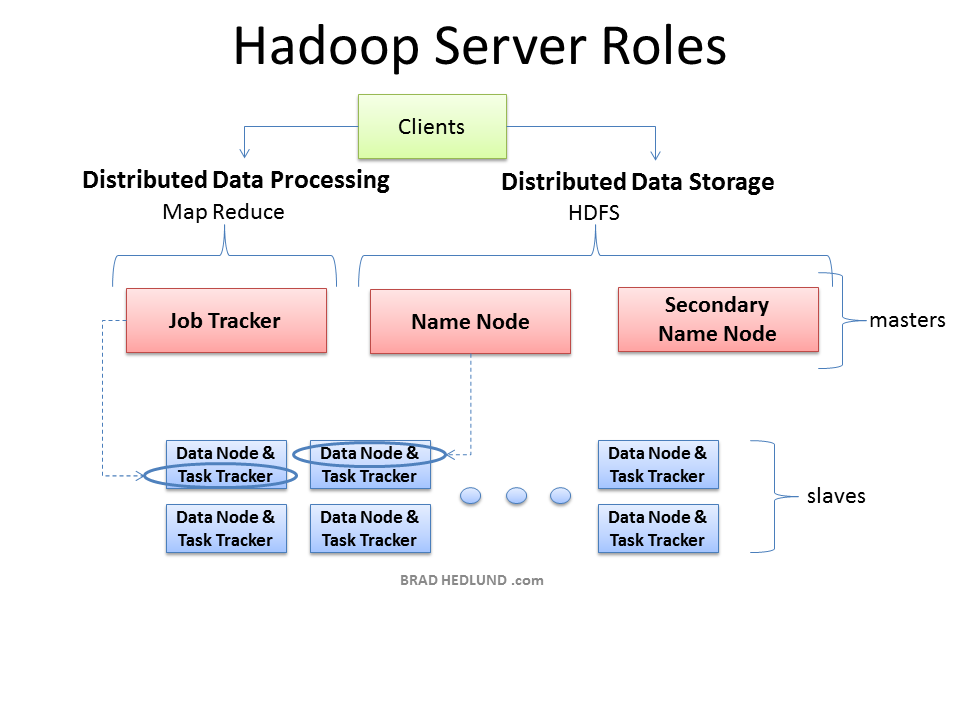
The three major categories of machine roles in a Hadoop deployment are Client machines, Masters nodes, and Slave nodes. The Master nodes oversee the two key functional pieces that make up Hadoop: storing lots of data (HDFS), and running parallel computations on all that data (Map Reduce). The Name Node oversees and coordinates the data storage function (HDFS), while the Job Tracker oversees and coordinates the parallel processing of data using Map Reduce. Slave Nodes make up the vast majority of machines and do all the dirty work of storing the data and running the computations. Each slave runs both a Data Node and Task Tracker daemon that communicate with and receive instructions from their master nodes. The Task Tracker daemon is a slave to the Job Tracker, the Data Node daemon a slave to the Name Node.
Hadoop部署的三个主要分类分别是Client machines、Masters nodes和Slave nodes。主节点监督两个重要的功能块形成Hadoop:存储大量数据(HDFS),在所有数据上并行计算(Map Reduce)。Name Node监督协调数据存储功能(HDFS),同时Job Tracker监督协调使用Map Reduce进行数据的并行处理。Slave Nodes形成大多数的机构,做着所有的存储数据和运行计算的脏活。每个slave同时运行着Data Node和Task Tracker的后台程序——用以传递和接收来自他们的master nodes的命令。Task Tracker后台程序是Job Tracker的slave,Data node后台程序是Name Node的slave。
Client machines have Hadoop installed with all the cluster settings, but are neither a Master or a Slave. Instead, the role of the Client machine is to load data into the cluster, submit Map Reduce jobs describing how that data should be processed, and then retrieve or view the results of the job when its finished. In smaller clusters (~40 nodes) you may have a single physical server playing multiple roles, such as both Job Tracker and Name Node. With medium to large clusters you will often have each role operating on a single server machine.
Client machines的Hadoop安装了所有的集群设置,但不包含Master或Slave。相应的,Client machine的作用是加载数据到集群,提交Map Reduce工作,描述数据应该怎么处理,然后在公众完成时取回或查看结果。在小一些的集群(约40个节点)中,你可能只有一个实体服务器运行多任务,例如Job Tracker和Name Node一样。在中大型集群你可能会在单个服务器中进行单个任务运转。
In real production clusters there is no server virtualization, no hypervisor layer. That would only amount to unnecessary overhead impeding performance. Hadoop runs best on Linux machines, working directly with the underlying hardware. That said, Hadoop does work in a virtual machine. That’s a great way to learn and get Hadoop up and running fast and cheap. I have a 6-node cluster up and running in VMware Workstation on my Windows 7 laptop.
在实际生产集群中没有服务器虚拟化,没有虚拟机监视器。那只会产生大量不必要的性能开支。Hadoop在Linux机器上运行得最好,直接在底层硬件上工作。也就是说,Hadoop在虚拟机上工作。那是了解和搭建Hadoop的好办法,并且运行的又快又便宜。我有一个6节点的集群,运行在我的Windows 7笔记本的VMware工作台上。
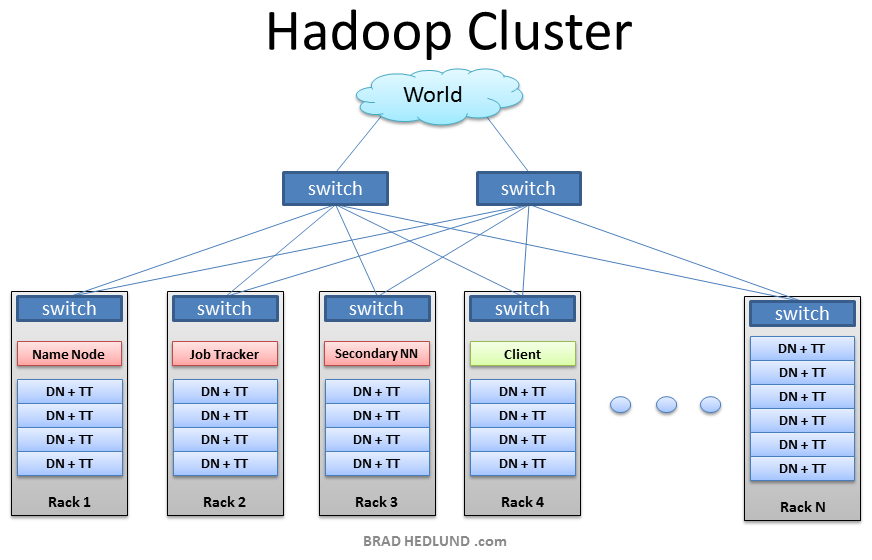
This is the typical architecture of a Hadoop cluster. You will have rack servers (not blades) populated in racks connected to a top of rack switch usually with 1 or 2 GE boned links. 10GE nodes are uncommon but gaining interest as machines continue to get more dense with CPU cores and disk drives. The rack switch has uplinks connected to another tier of switches connecting all the other racks with uniform bandwidth, forming the cluster. The majority of the servers will be Slave nodes with lots of local disk storage and moderate amounts of CPU and DRAM. Some of the machines will be Master nodes that might have a slightly different configuration favoring more DRAM and CPU, less local storage. In this post, we are not going to discuss various detailed network design options. Let’s save that for another discussion (stay tuned). First, lets understand how this application works…
这是一个Hadoop集群的典型结构。你将使用机架服务器(不是刀锋服务器),搭建在机架中,连接一个顶部机架开关,通常使用1或2 GE(Gigabit Ethernet千兆以太网)。10 GE节点是不常有的,但当机器使用CPU核心和磁盘驱动获取更大的密度时收益更多。机架开关上行传输被连接到连接所有其他相同带宽机架的另一层开关,构成集群。大多数服务器是Slave nodes,使用大量的本地磁盘存储和中量的CPU和DRAM。一些机器是Master nodes,可能有轻微不同的配置,使用更多的DRAM和CPU,较少的本地存储。在这片文章中,我们不讨论许多详细的网络设计选择,让我们将它保留到另一个讨论(在调试中)中。首先,让我们理解这个应用怎么工作的。

Why did Hadoop come to exist? What problem does it solve? Simply put, businesses and governments have a tremendous amount of data that needs to be analyzed and processed very quickly. If I can chop that huge chunk of data into small chunks and spread it out over many machines, and have all those machines processes their portion of the data in parallel – I can get answers extremely fast – and that, in a nutshell, is what Hadoop does. In our simple example, we’ll have a huge data file containing emails sent to the customer service department. I want a quick snapshot to see how many times the word “Refund” was typed by my customers. This might help me to anticipate the demand on our returns and exchanges department, and staff it appropriately. It’s a simple word count exercise. The Client will load the data into the cluster (File.txt), submit a job describing how to analyze that data (word count), the cluster will store the results in a new file (Results.txt), and the Client will read the results file.
Hadoop为何诞生?它解决了什么问题?简言之,商业和政府有一个极大量的数据需要非常快地分析和处理。如果我可以分离这个巨大的数据到很多小的部分,铺开到大量的机器中,让这些机器并行处理它们各自的那一部分——我就可以极快的获取结果——这就是Hadoop做的事情。在我们的简单例子中,我们将用一个巨大的数据文件,它包含了发送到客户服务部门的邮件。我想要一个数据快照,来查看单词“Refund”被客户输入了多少次。这将有助于我预测退还和交换部门的需求,并且合理地安排职员。这是一个简单的词条计数训练。Clients将会加载数据到集群(File.txt),提交一个工作描述,如何分析数据(单词计数),集群会存储结果到一个新的文件(Results.txt),然后Clients会读取结果文件。
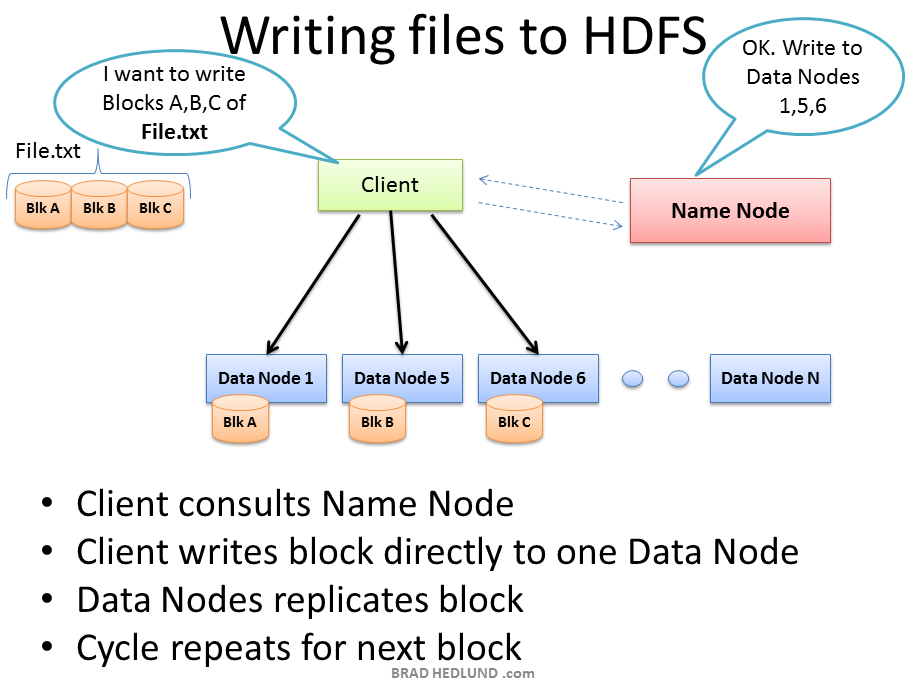
Your Hadoop cluster is useless until it has data, so we’ll begin by loading our huge File.txt into the cluster for processing. The goal here is fast parallel processing of lots of data. To accomplish that I need as many machines as possible working on this data all at once. To that end, the Client is going to break the data file into smaller “Blocks”, and place those blocks on different machines throughout the cluster. The more blocks I have, the more machines that will be able to work on this data in parallel. At the same time, these machines may be prone to failure, so I want to insure that every block of data is on multiple machines at once to avoid data loss. So each block will be replicated in the cluster as its loaded. The standard setting for Hadoop is to have (3) copies of each block in the cluster. This can be configured with the dfs.replication parameter in the file hdfs-site.xml.
你的Hadoop集群直到有数据才有用,所以我们开始于加载超大的File.txt到集群中处理。这里的目标是快速并行处理大量数据。为此我需要尽可能多的机器同时处理这些数据。在那结束后,Client将会打断这个数据文件为许多小的块,将这些块放到遍及集群的不同的机器上。分成的块越多,能并行工作的机器就越多。在同一时间,这些机器可能容易失败,所以为了避免数据丢失,我会确信每个数据块在多台机器上存在。所以每个块会在加载到集群时复制。Hadoop的标准设置是集群中每个块有3个复制。这个可以在hdfs-site.xml文件的dfs.replication参数中设置。
The Client breaks File.txt into (3) Blocks. For each block, the Client consults the Name Node (usually TCP 9000) and receives a list of (3) Data Nodes that should have a copy of this block. The Client then writes the block directly to the Data Node (usually TCP 50010). The receiving Data Node replicates the block to other Data Nodes, and the cycle repeats for the remaining blocks. The Name Node is not in the data path. The Name Node only provides the map of where data is and where data should go in the cluster (file system metadata).
Client将File.txt拆分为3个块。对每个块,Client查看Name Node(通常用TCP 9000)并接收一个3个Data Nodes的list,每个Data Node都是一个块的复制。Client将块直接写入到Data Node(通常用TCP 50010)。收到的Data Node将块复制到其他Data Nodes,剩下的块也循环这个重复过程。Name Node不是数据路径。在集群中(文件系统云数据)Name Node只提供数据的位置和数据应该去哪。
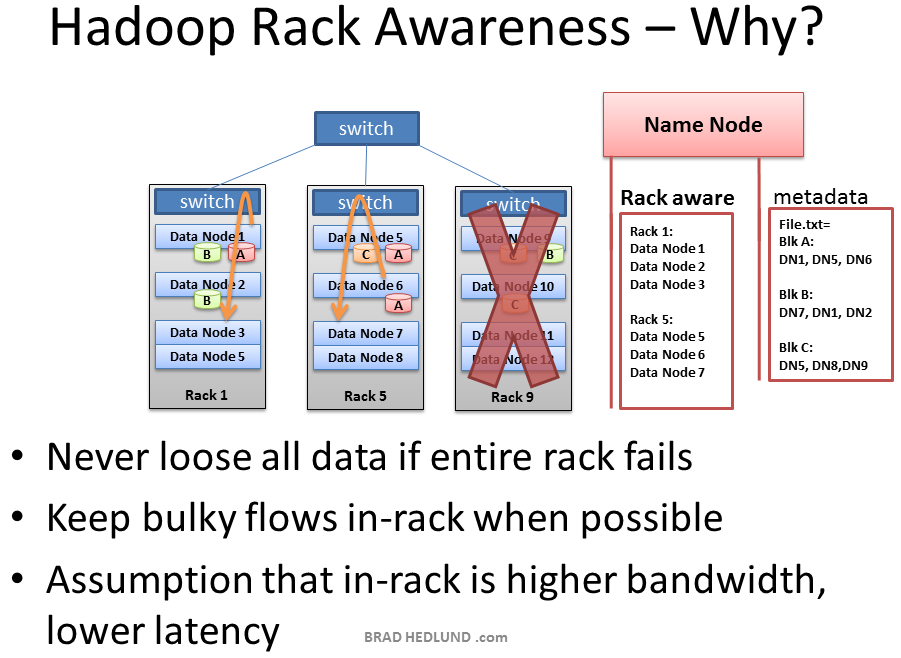
Hadoop has the concept of “Rack Awareness”. As the Hadoop administrator you can manually define the rack number of each slave Data Node in your cluster. Why would you go through the trouble of doing this? There are two key reasons for this: Data loss prevention, and network performance. Remember that each block of data will be replicated to multiple machines to prevent the failure of one machine from losing all copies of data. Wouldn’t it be unfortunate if all copies of data happened to be located on machines in the same rack, and that rack experiences a failure? Such as a switch failure or power failure. That would be a mess. So to avoid this, somebody needs to know where Data Nodes are located in the network topology and use that information to make an intelligent decision about where data replicas should exist in the cluster. That “somebody” is the Name Node.
Hadoop有“机架感知”的概念。作为Hadoop管理员,你可以手动定义集群中每个slave Data Noded的机架数量。为什么你要做这个麻烦的事情呢?有两个关键原因:防止数据丢失和网络性能。记住每个块的数据需要复制到多个机器以防止一个机器失败是丢失所有的数据。如果所有的数据复制碰巧位于同意机架的机器上,并且机架发生失败,会发生这样的事情吗?比如一个开关失败或者是供电问题。那将会一团糟。所以为了避免这样,“某物”需要知道网络拓扑中Data Nodes在哪,以此做一个关于数据复制品应该存放在集群何处的智能的决定。这个“某物”是Name Node。
There is also an assumption that two machines in the same rack have more bandwidth and lower latency between each other than two machines in two different racks. This is true most of the time. The rack switch uplink bandwidth is usually (but not always) less than its downlink bandwidth. Furthermore, in-rack latency is usually lower than cross-rack latency (but not always). If at least one of those two basic assumptions are true, wouldn’t it be cool if Hadoop can use the same Rack Awareness that protects data to also optimally place work streams in the cluster, improving network performance? Well, it does! Cool, right?
有一个假设关于在同一机架的两个机器之间比起不同机架的两个机器有更多的带宽和更低的等待时间。大多是时候这是正确的。机架开关的上行带宽通常(不总是)比下行带宽小。而且,在机架内的等待时间通常比机架见的等待时间低(不总是)。如果这两个基础假设中至少一个是对的,如果Hadoop能用同一个机架感知,保护数据到工作流也就是集群中最适宜的位置,提高网络性能,不会更好吗?当然会。
What is NOT cool about Rack Awareness at this point is the manual work required to define it the first time, continually update it, and keep the information accurate. If the rack switch could auto-magically provide the Name Node with the list of Data Nodes it has, that would be cool. Or vice versa, if the Data Nodes could auto-magically tell the Name Node what switch they’re connected to, that would be cool too.
在这一点关于机架感知不好的地方是,manual work required to define it the first time,持续的更新它,保持信息准确。如果机架可以自动提供Data Nodes list的Name Node,那将会很好。反过来也是,如果Data Nodes可以自动告诉Name Node它们连接的什么开关,也会很好。
Even more interesting would be a OpenFlow network, where the Name Node could query the OpenFlow controller about a Node’s location in the topology.
甚至更有趣的是一个OpenFlow network,Name Node可以在哪查询OpenFlow控制器关于一个Node的拓扑位置。
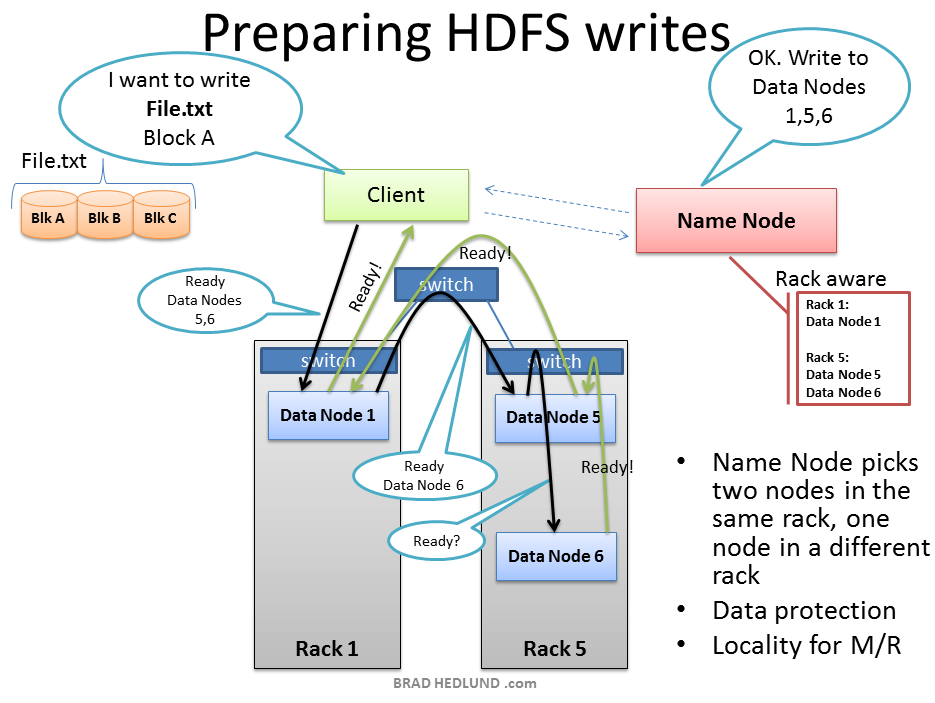
The Client is ready to load File.txt into the cluster and breaks it up into blocks, starting with Block A. The Client consults the Name Node that it wants to write File.txt, gets permission from the Name Node, and receives a list of (3) Data Nodes for each block, a unique list for each block. The Name Node used its Rack Awareness data to influence the decision of which Data Nodes to provide in these lists. The key rule is that for every block of data, two copies will exist in one rack, another copy in a different rack. So the list provided to the Client will follow this rule.
Client准备好加载文件到集群中,将它打断到不同的块,开始块A。Client查询Name Node,想写入File.txt,从Name Node获取许可,接收一个包含每个块的Data Node的list,一个包含每个块独有的list。Name Node用它的机架感知数据去影响这些list中提供哪个Data Nodes的决定。重要规则是对数据的每个块,两个复制存在一个机架中,另一个复制在其他机架中。所以这个list提供Client将遵循这个规则。
Before the Client writes “Block A” of File.txt to the cluster it wants to know that all Data Nodes which are expected to have a copy of this block are ready to receive it. It picks the first Data Node in the list for Block A (Data Node 1), opens a TCP 50010 connection and says, “Hey, get ready to receive a block, and here’s a list of (2) Data Nodes, Data Node 5 and Data Node 6. Go make sure they’re ready to receive this block too.” Data Node 1 then opens a TCP connection to Data Node 5 and says, “Hey, get ready to receive a block, and go make sure Data Node 6 is ready is receive this block too.” Data Node 5 will then ask Data Node 6, “Hey, are you ready to receive a block?”
在Client写入块到File.txt之前,它想知道所有的Data Nodes哪个期望准备接收一个这个块的复制。它在list中为块A挑选第一个Data Node(Data Node 1),打开TCP 50010连接,然后说,“嘿,准备好接收一个块,这是两个Data Node的list,Data Node 5和Data Node 6。去确信它们也准备好接收这个块。”然后Data Node 1打开一个TCP连接到Data Node 5然后说,“嘿,准备好接收一个块,去确信Data Node 6也准备好接收这个块。”Data Node 5将问Data Node 6,“嘿,你准备好接收一个块了吗?”
The acknowledgments of readiness come back on the same TCP pipeline, until the initial Data Node 1 sends a “Ready” message back to the Client. At this point the Client is ready to begin writing block data into the cluster.
准备就绪的确认通知在同一TCP管道返回,直到初始的Data Node 1发送一个“Ready”信息给Client。这样,Client就准备好开始写入块数据到集群中。
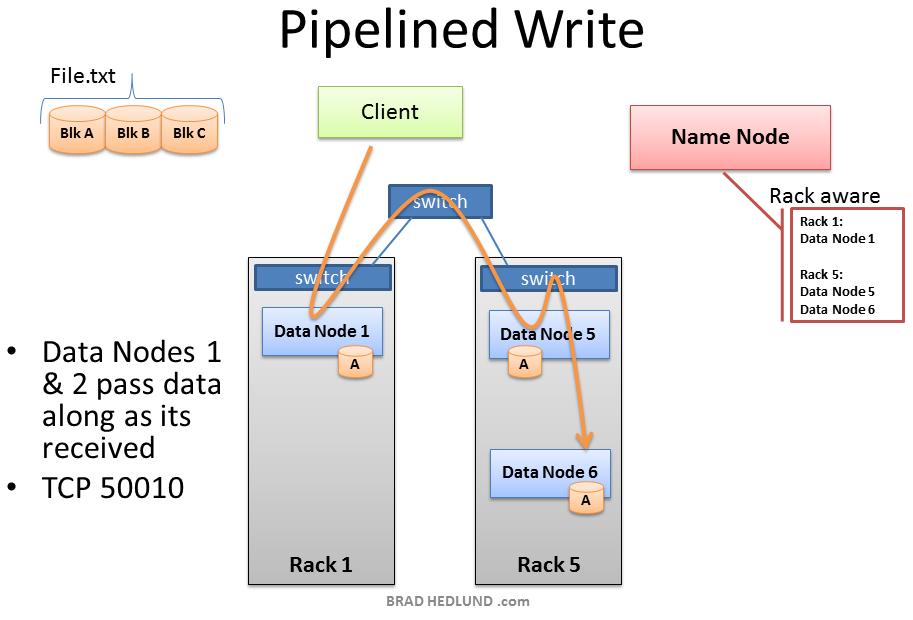
As data for each block is written into the cluster a replication pipeline is created between the (3) Data Nodes (or however many you have configured in dfs.replication). This means that as a Data Node is receiving block data it will at the same time push a copy of that data to the next Node in the pipeline.
当每个块的数据被写入集群时, 三个Data Nodes之间(或者无论多少个你在dfs.replication中设置的)会创建一个复制管道. 这意味着, 当一个Data Node接收数据块时, 它会同时推送一个数据的复制到管道中的下一个Node.
Here too is a primary example of leveraging the Rack Awareness data in the Name Node to improve cluster performance. Notice that the second and third Data Nodes in the pipeline are in the same rack, and therefore the final leg of the pipeline does not need to traverse between racks and instead benefits from in-rack bandwidth and low latency. The next block will not be begin until this block is successfully written to all three nodes.
这也是一个借助机架系统的简单例子, Name Node中的数据提升集群性能. 注意管道中的第二个和第三个Data Node位于同一个机架中, 因此管道的最后一步不用穿过机架, 这会带来机架内的带宽和低延迟收益. 下一个数据块会在这一块成功写入到三个Nodes后开始.
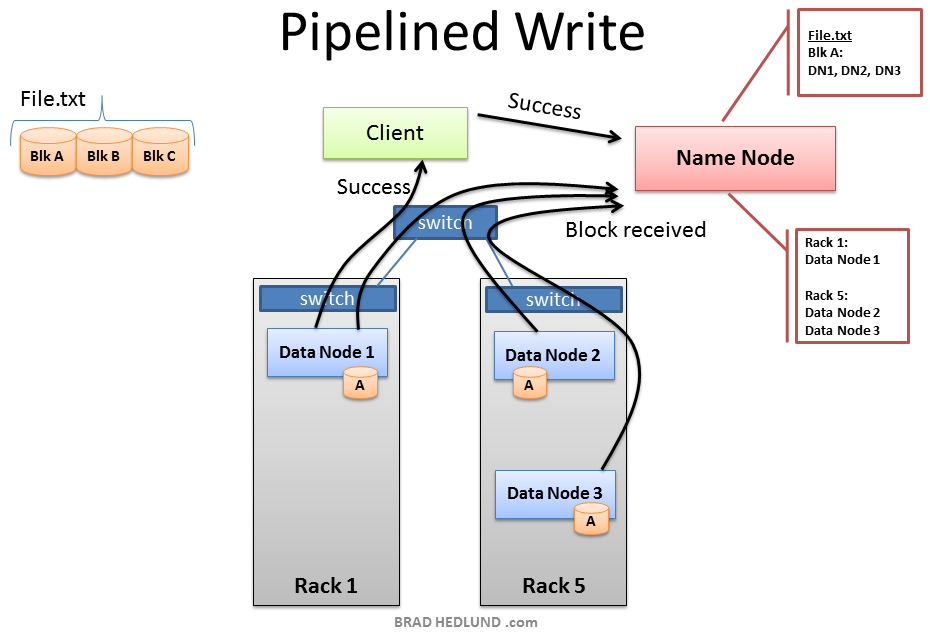
When all three Nodes have successfully received the block they will send a “Block Received” report to the Name Node. They will also send “Success” messages back up the pipeline and close down the TCP sessions. The Client receives a success message and tells the Name Node the block was successfully written. The Name Node updates it metadata info with the Node locations of Block A in File.txt. The Client is ready to start the pipeline process again for the next block of data.
当所有的三个Node都成功接收了这个块, 它们会发送一个”Block Received”报告给Name Node. 它们也会给管道返回一个”Success”消息并关闭TCP协议. Client接收了一个Success消息, 通知Name Node块已经成功写入. Name Node更新File.txt中块A的Node位置的元数据信息. Client准备好开始下一个数据块的管道处理.
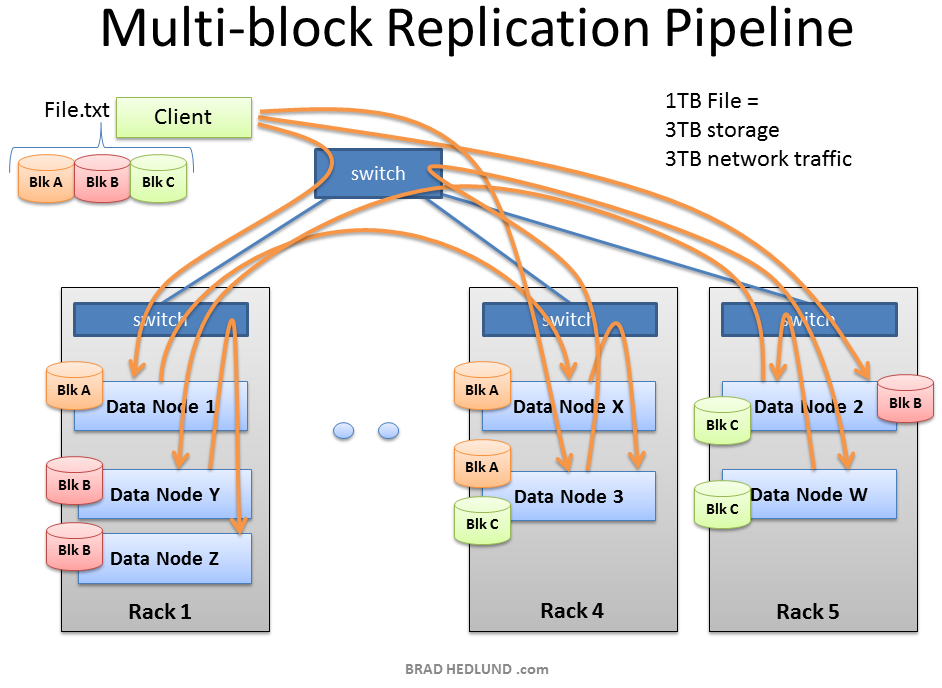
As the subsequent blocks of File.txt are written, the initial node in the pipeline will vary for each block, spreading around the hot spots of in-rack and cross-rack traffic for replication.
当File.txt中随后的块都被写入, 管道中初始的node会为每一个块做相应的变化, 在机架内的热点间传播, 在机架间复制.
Hadoop uses a lot of network bandwidth and storage. We are typically dealing with very big files, Terabytes in size. And each file will be replicated onto the network and disk (3) times. If you have a 1TB file it will consume 3TB of network traffic to successfully load the file, and 3TB disk space to hold the file.
Hadoop使用大量的网络带宽和存储空间. 特别是当我们处理非常大的文件时, TB量级的. 每个文件将3倍地复制到网络和磁盘上. 如果你有一个1TB的文件, 它将消耗3TB的网络来成功地加载文件, 以及3TB的磁盘空间来保存这个文件.
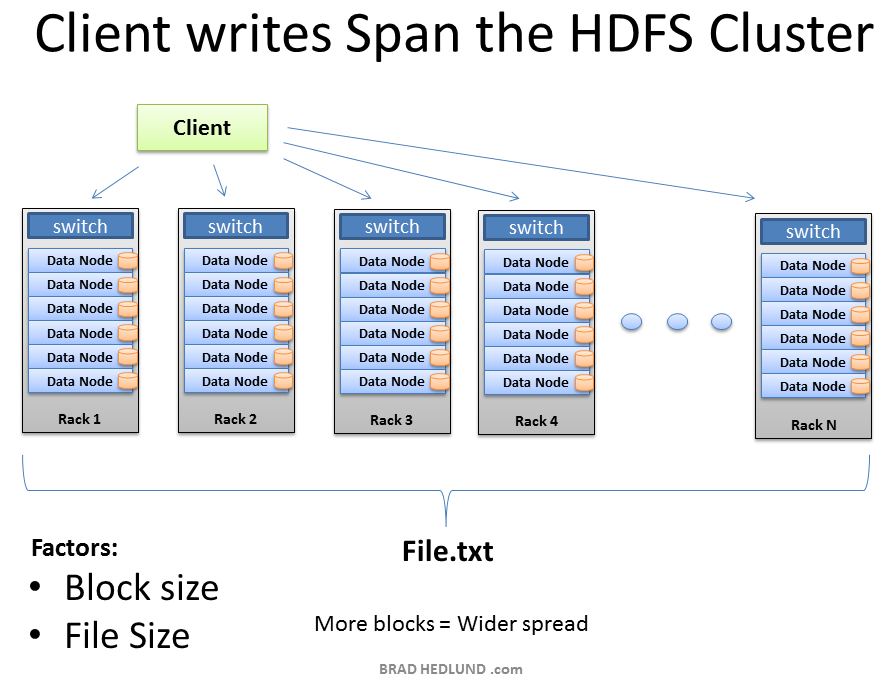
After the replication pipeline of each block is complete the file is successfully written to the cluster. As intended the file is spread in blocks across the cluster of machines, each machine having a relatively small part of the data. The more blocks that make up a file, the more machines the data can potentially spread. The more CPU cores and disk drives that have a piece of my data mean more parallel processing power and faster results. This is the motivation behind building large, wide clusters. To process more data, faster. When the machine count goes up and the cluster goes wide, our network needs to scale appropriately.
在每个块的复制管道都完成后, 文件就成功地写入集群了. 为了文件在集群机器的块之间传播, 每个机器有相对小的一部分数据. 文件分割的块越多, 数据可能传播的机器就越多. 一块数据有更多的CPU核心和磁盘驱动意味着更好的并行处理能力和更快的获得结果. 这是建立更大更宽的集群的背后的动机. 为了更快处理更多的数据. 当机器数增长, 集群变宽, 我们的网络需要合适的规模.
Another approach to scaling the cluster is to go deep. This is where you scale up the machines with more disk drives and more CPU cores. Instead of increasing the number of machines you begin to look at increasing the density of each machine. In scaling deep, you put yourself on a trajectory where more network I/O requirements may be demanded of fewer machines. In this model, how your Hadoop cluster makes the transition to 10GE nodes becomes an important consideration.
纵向发展是规模化集群的另一种方法. 这即是你用更多的磁盘驱动和更多的CPU核数纵向扩展机器. 相对增加机器数量, 取而代之的是增加每个机器的密度. 在纵向化时, 你将趋向于更多的网络I/O需求使用更少的机器. 在这种模式下, 你的Hasoop集群怎样变迁到10GE nodes成为一个重点.
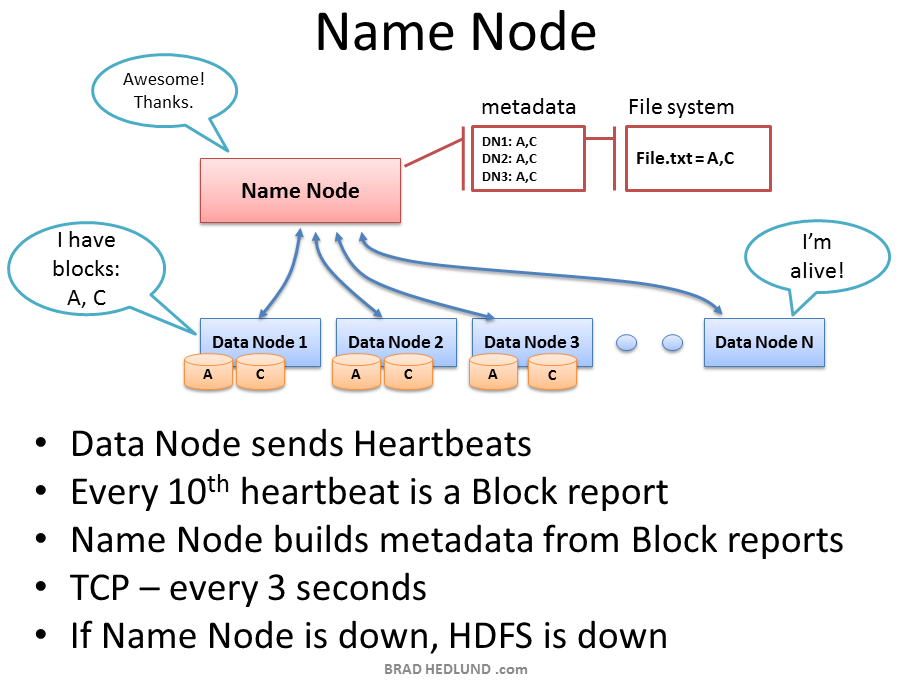
The Name Node holds all the file system metadata for the cluster and oversees the health of Data Nodes and coordinates access to data. The Name Node is the central controller of HDFS. It does not hold any cluster data itself. The Name Node only knows what blocks make up a file and where those blocks are located in the cluster. The Name Node points Clients to the Data Nodes they need to talk to and keeps track of the cluster’s storage capacity, the health of each Data Node, and making sure each block of data is meeting the minimum defined replica policy.
Name Node控制集群的所有的文件系统元数据, 监督Data Nodes的健康和协调数据入口. Name Node时HDFS的控制中心. 它自己不控制任何集群数据. Name Node只知道文件由什么块组成, 和那些块在集群中的位置. Name Node从Client指向Data Nodes, 它们需要交流来保持集群存储能力和每个Data Node健康的轨迹, 并且确认每个数据的块保证最低限度的复制.
Data Nodes send heartbeats to the Name Node every 3 seconds via a TCP handshake, using the same port number defined for the Name Node daemon, usually TCP 9000. Every tenth heartbeat is a Block Report, where the Data Node tells the Name Node about all the blocks it has. The block reports allow the Name Node build its metadata and insure (3) copies of the block exist on different nodes, in different racks.
Data Node通过TCP握手每3秒发送心跳给Name Node, 为Name Node使用同一个确定的端口号, 通常是TCP 9000. 每第10个心跳是一个块报告, 关于Data Node告诉Name Node所有它有的块. 块报告允许Name Node建立它的元数据和确认块的3个复制存在于不同机架的不同的node上.
The Name Node is a critical component of the Hadoop Distributed File System (HDFS). Without it, Clients would not be able to write or read files from HDFS, and it would be impossible to schedule and execute Map Reduce jobs. Because of this, it’s a good idea to equip the Name Node with a highly redundant enterprise class server configuration; dual power supplies, hot swappable fans, redundant NIC connections, etc.
Name Node是Hadoop分布式文件系统的一个关键的组件. 没有它, Clients将不能从HDFS写和读文件, 而且也不能规划和执行Map Reduce工作. 归功于它, 用高冗余企业类服务器配置安装Name Node是一个好主意. 双重支持, 热交换, 冗余NIC连接, 等.
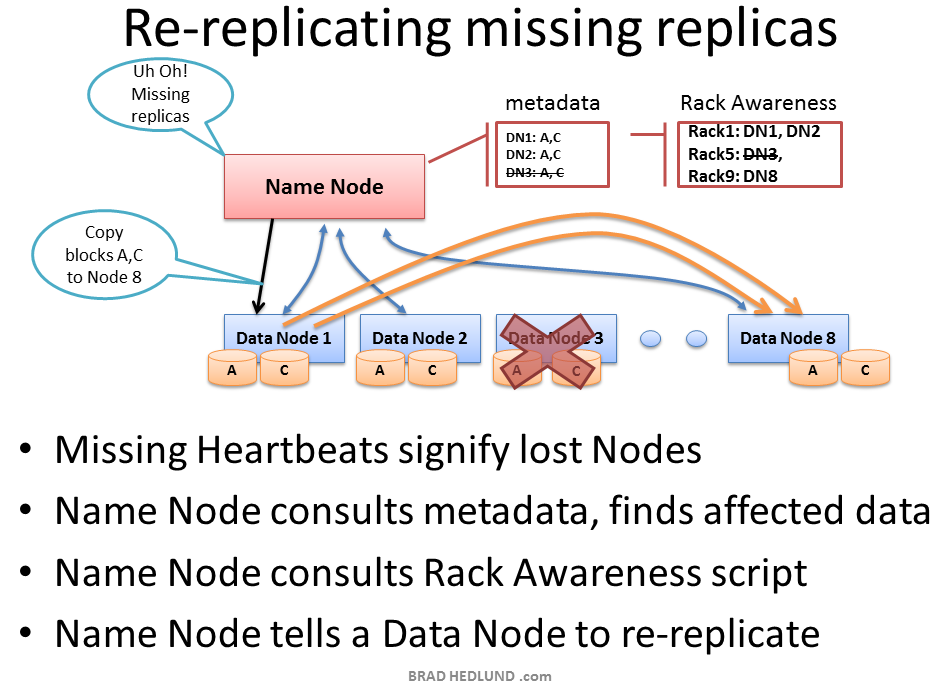
If the Name Node stops receiving heartbeats from a Data Node it presumes it to be dead and any data it had to be gone as well. Based on the block reports it had been receiving from the dead node, the Name Node knows which copies of blocks died along with the node and can make the decision to re-replicate those blocks to other Data Nodes. It will also consult the Rack Awareness data in order to maintain the two copies in one rack, one copy in another rack replica rule when deciding which Data Node should receive a new copy of the blocks.
Consider the scenario where an entire rack of servers falls off the network, perhaps because of a rack switch failure, or power failure. The Name Node would begin instructing the remaining nodes in the cluster to re-replicate all of the data blocks lost in that rack. If each server in that rack had a modest 12TB of data, this could be hundreds of terabytes of data that needs to begin traversing the network.
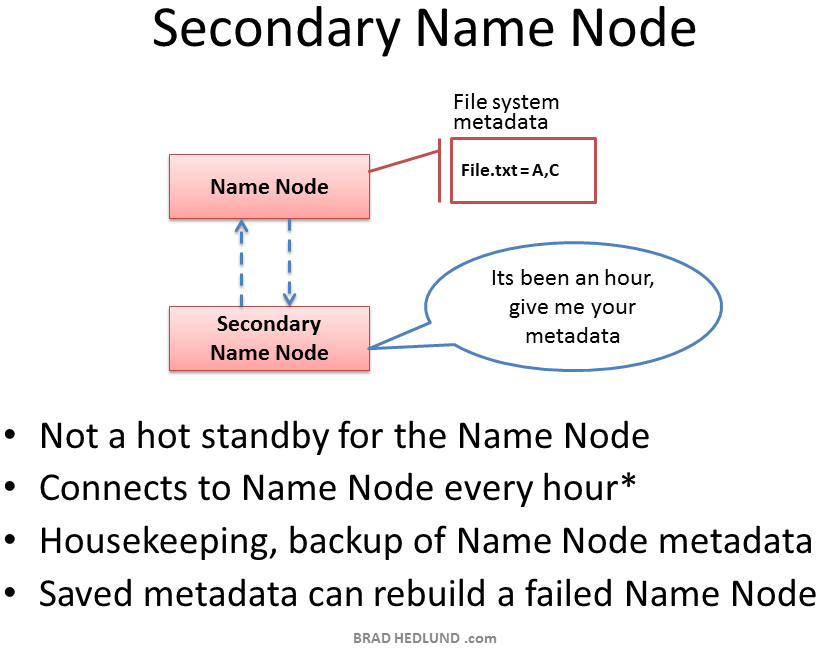
Hadoop has server role called the Secondary Name Node. A common misconception is that this role provides a high availability backup for the Name Node. This is not the case.
The Secondary Name Node occasionally connects to the Name Node (by default, ever hour) and grabs a copy of the Name Node’s in-memory metadata and files used to store metadata (both of which may be out of sync). The Secondary Name Node combines this information in a fresh set of files and delivers them back to the Name Node, while keeping a copy for itself.
Should the Name Node die, the files retained by the Secondary Name Node can be used to recover the Name Node. In a busy cluster, the administrator may configure the Secondary Name Node to provide this housekeeping service much more frequently than the default setting of one hour. Maybe every minute.
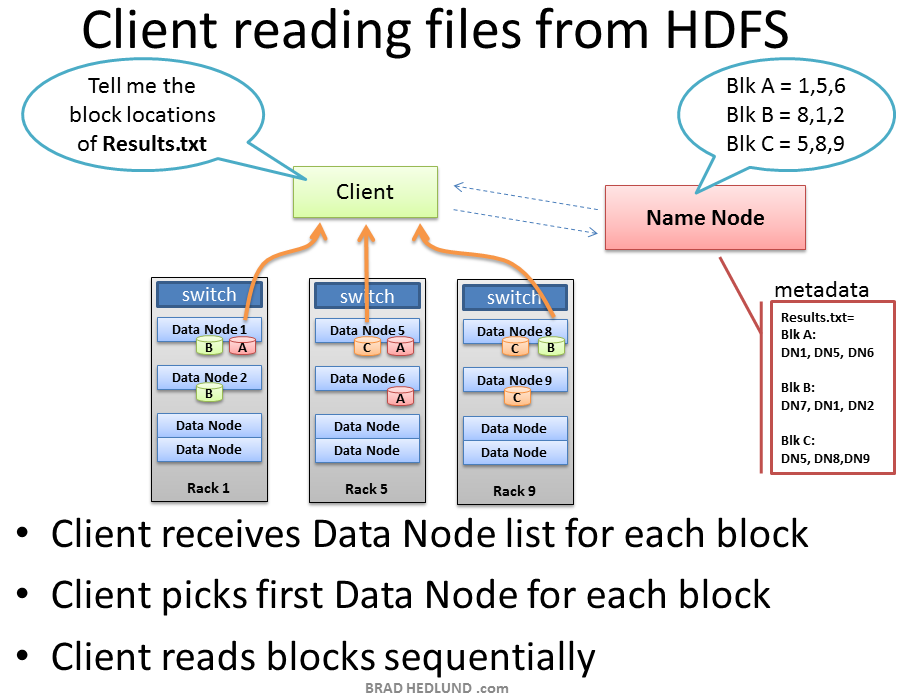
When a Client wants to retrieve a file from HDFS, perhaps the output of a job, it again consults the Name Node and asks for the block locations of the file. The Name Node returns a list of each Data Node holding a block, for each block. The Client picks a Data Node from each block list and reads one block at a time with TCP on port 50010, the default port number for the Data Node daemon. It does not progress to the next block until the previous block completes.
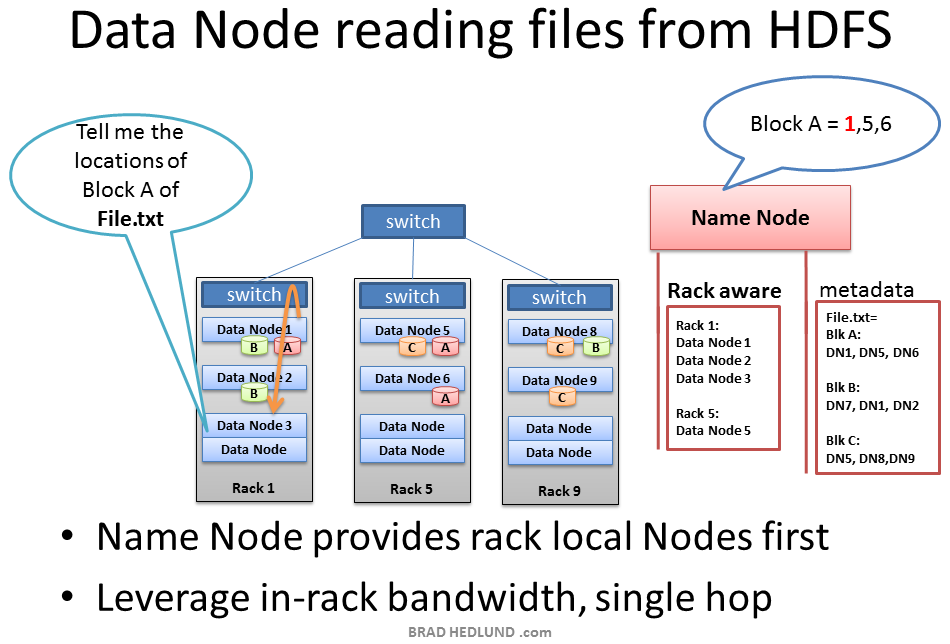
There are some cases in which a Data Node daemon itself will need to read a block of data from HDFS. One such case is where the Data Node has been asked to process data that it does not have locally, and therefore it must retrieve the data from another Data Node over the network before it can begin processing.
This is another key example of the Name Node’s Rack Awareness knowledge providing optimal network behavior. When the Data Node asks the Name Node for location of block data, the Name Node will check if another Data Node in the same rack has the data. If so, the Name Node provides the in-rack location from which to retrieve the data. The flow does not need to traverse two more switches and congested links find the data in another rack. With the data retrieved quicker in-rack, the data processing can begin sooner, and the job completes that much faster.
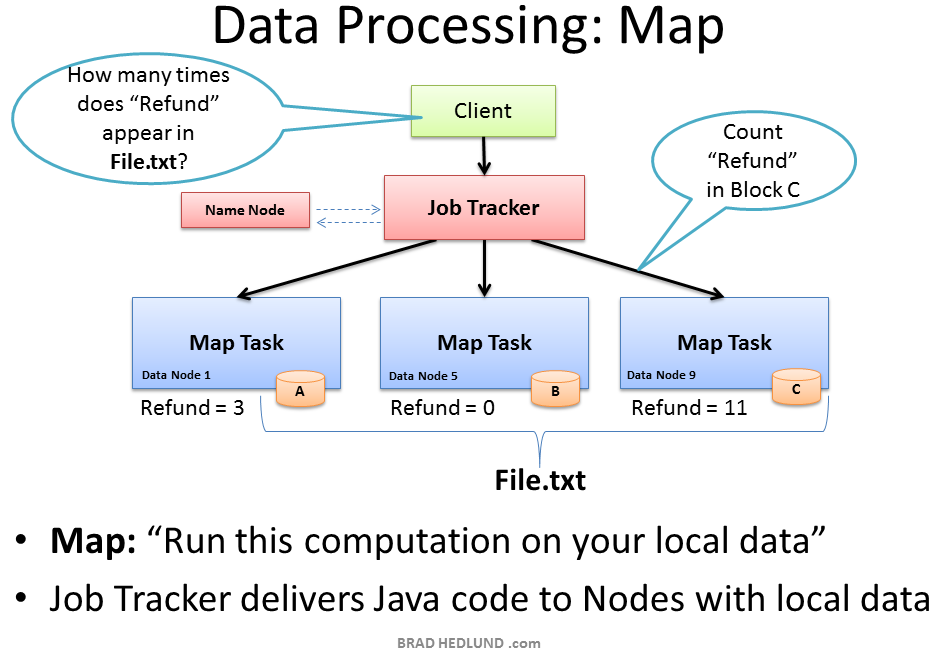
Now that File.txt is spread in small blocks across my cluster of machines I have the opportunity to provide extremely fast and efficient parallel processing of that data. The parallel processing framework included with Hadoop is called Map Reduce, named after two important steps in the model; Map, and Reduce.
The first step is the Map process. This is where we simultaneously ask our machines to run a computation on their local block of data. In this case we are asking our machines to count the number of occurrences of the word “Refund” in the data blocks of File.txt.
To start this process the Client machine submits the Map Reduce job to the Job Tracker, asking “How many times does Refund occur in File.txt” (paraphrasing Java code). The Job Tracker consults the Name Node to learn which Data Nodes have blocks of File.txt. The Job Tracker then provides the Task Tracker running on those nodes with the Java code required to execute the Map computation on their local data. The Task Tracker starts a Map task and monitors the tasks progress. The Task Tracker provides heartbeats and task status back to the Job Tracker.
As each Map task completes, each node stores the result of its local computation in temporary local storage. This is called the “intermediate data”. The next step will be to send this intermediate data over the network to a Node running a Reduce task for final computation.
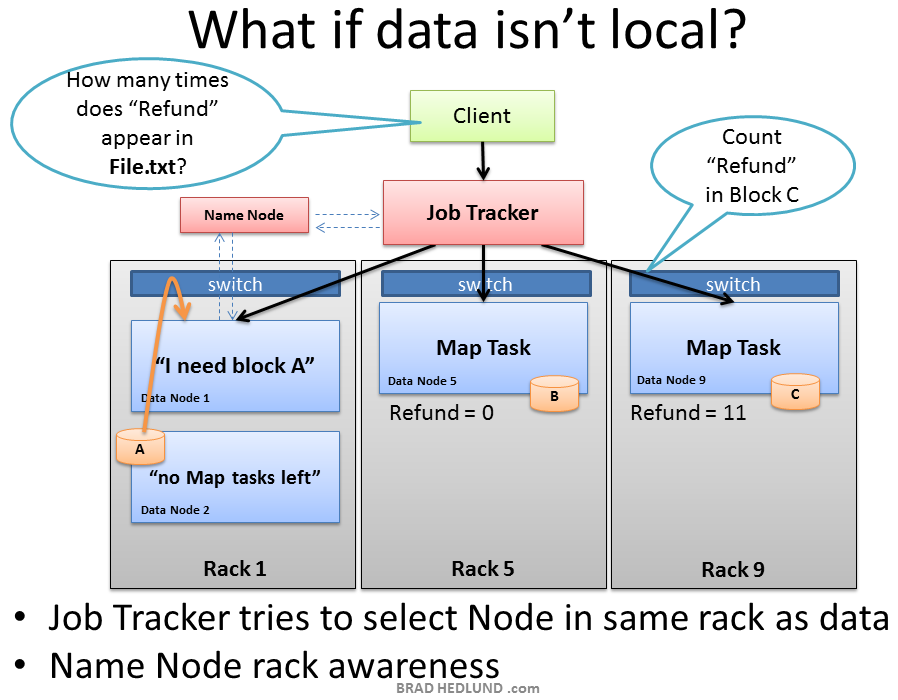
While the Job Tracker will always try to pick nodes with local data for a Map task, it may not always be able to do so. One reason for this might be that all of the nodes with local data already have too many other tasks running and cannot accept anymore. In this case, the Job Tracker will consult the Name Node whose Rack Awareness knowledge can suggest other nodes in the same rack. The Job Tracker will assign the task to a node in the same rack, and when that node goes to find the data it needs the Name Node will instruct it to grab the data from another node in its rack, leveraging the presumed single hop and high bandwidth of in-rack switching.
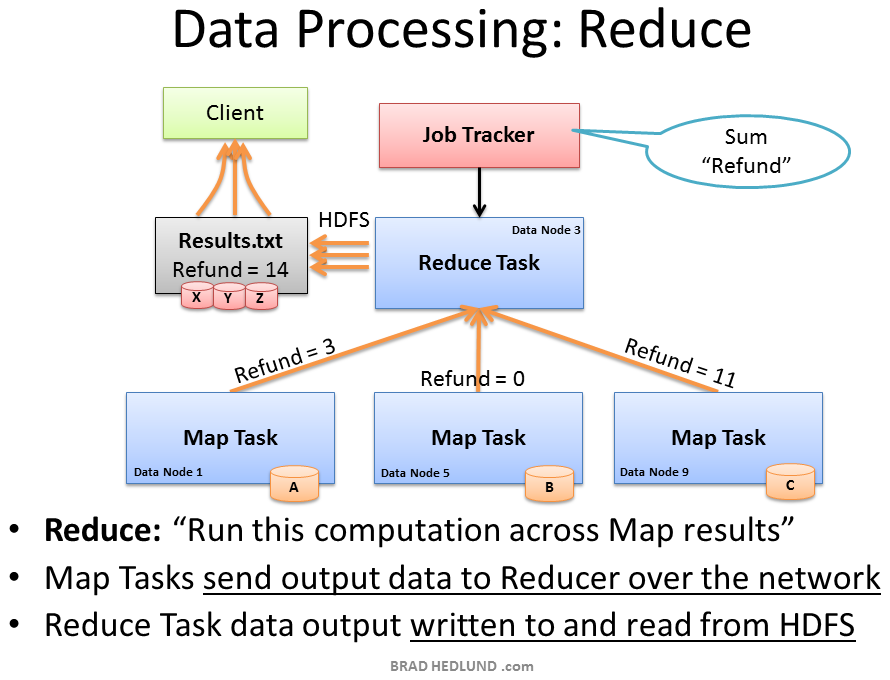
The second phase of the Map Reduce framework is called, you guess it, Reduce. The Map task on the machines have completed and generated their intermediate data. Now we need to gather all of this intermediate data to combine and distill it for further processing such that we have one final result.
The Job Tracker starts a Reduce task on any one of the nodes in the cluster and instructs the Reduce task to go grab the intermediate data from all of the completed Map tasks. The Map tasks may respond to the Reducer almost simultaneously, resulting in a situation where you have a number of nodes sending TCP data to a single node, all at once. This traffic condition is often referred to as TCP Incast or “fan-in”. For networks handling lots of Incast conditions, it’s important the network switches have well-engineered internal traffic management capabilities, and adequate buffers (not too big, not too small). Throwing gobs of buffers at a switch may end up causing unwanted collateral damage to other traffic. But that’s a topic for another day.
The Reducer task has now collected all of the intermediate data from the Map tasks and can begin the final computation phase. In this case, we are simply adding up the sum total occurrences of the word “Refund” and writing the result to a file called Results.txt
The output from the job is a file called Results.txt that is written to HDFS following all of the processes we have covered already; splitting the file up into blocks, pipeline replication of those blocks, etc. When complete, the Client machine can read the Results.txt file from HDFS, and the job is considered complete.
Our simple word count job did not result in a lot of intermediate data to transfer over the network. Other jobs however may produce a lot of intermediate data – such as sorting a terabyte of data. Where the output of the Map Reduce job is a new set of data equal to the size of data you started with. How much traffic you see on the network in the Map Reduce process is entirely dependent on the type job you are running at that given time.
If you’re a studious network administrator, you would learn more about Map Reduce and the types of jobs your cluster will be running, and how the type of job affects the traffic flows on your network. If you’re a Hadoop networking rock star, you might even be able to suggest ways to better code the Map Reduce jobs so as to optimize the performance of the network, resulting in faster job completion times.
Hadoop may start to be a real success in your organization, providing a lot of previously untapped business value from all that data sitting around. When business folks find out about this you can bet that you’ll quickly have more money to buy more racks of servers and network for your Hadoop cluster.
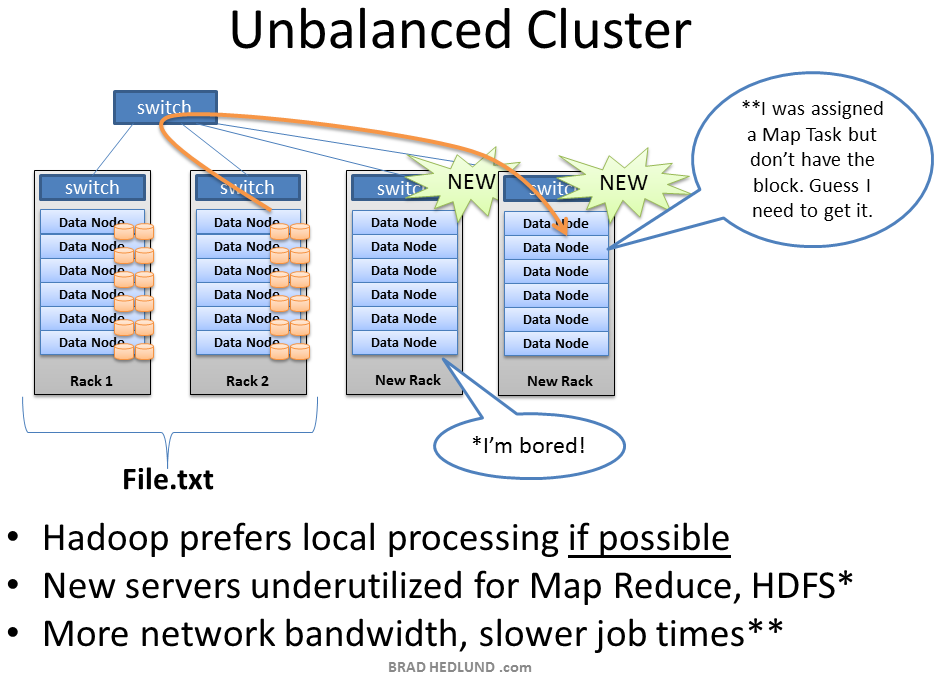
When you add new racks full of servers and network to an existing Hadoop cluster you can end up in a situation where your cluster is unbalanced. In this case, Racks 1 & 2 were my existing racks containing File.txt and running my Map Reduce jobs on that data. When I added two new racks to the cluster, my File.txt data doesn’t auto-magically start spreading over to the new racks. All the data stays where it is.
The new servers are sitting idle with no data, until I start loading new data into the cluster. Furthermore, if the servers in Racks 1 & 2 are really busy, the Job Tracker may have no other choice but to assign Map tasks on File.txt to the new servers which have no local data. The new servers need to go grab the data over the network. As as result you may see more network traffic and slower job completion times.
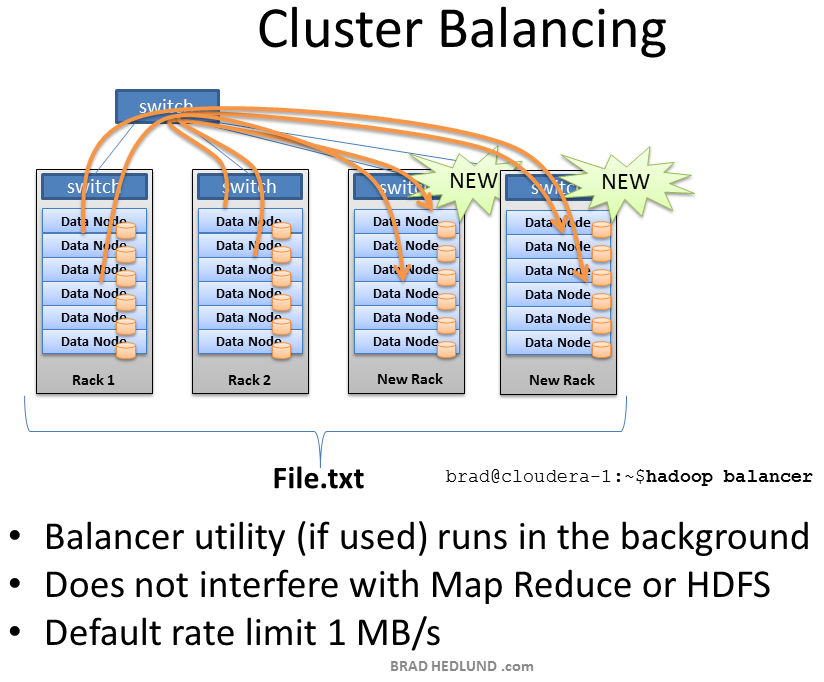
To fix the unbalanced cluster situation, Hadoop includes a nifty utility called, you guessed it, balancer.
Balancer looks at the difference in available storage between nodes and attempts to provide balance to a certain threshold. New nodes with lots of free disk space will be detected and balancer can begin copying block data off nodes with less available space to the new nodes. Balancer isn’t running until someone types the command at a terminal, and it stops when the terminal is canceled or closed.
The amount of network traffic balancer can use is very low, with a default setting of 1MB/s. This setting can be changed with the dfs.balance.bandwidthPerSec parameter in the file hdfs-site.xml
The Balancer is good housekeeping for your cluster. It should definitely be used any time new machines are added, and perhaps even run once a week for good measure. Given the balancers low default bandwidth setting it can take a long time to finish its work, perhaps days or weeks. Wouldn’t it be cool if cluster balancing was a core part of Hadoop, and not just a utility? I think so.
This material is based on studies, training from Cloudera, and observations from my own virtual Hadoop lab of six nodes. Everything discussed here is based on the latest stable release of Cloudera’s CDH3 distribution of Hadoop. There are new and interesting technologies coming to Hadoop such as Hadoop on Demand (HOD) and HDFS Federations, not discussed here, but worth investigating on your own if so inclined.
Download: Slides - PDF Slides and Text - PDF
Cheers, Brad